
SAN FRANCISCO, Aug. 07, 2025 (GLOBE NEWSWIRE) -- Silicon Valley startup, iFrame™ AI, has quietly secured a nearly $20 million deal with a leading cloud provider to launch the world’s first Large Attention Model with an infinite context window - a breakthrough poised to disrupt the professional services industry and undercut OpenAI-like companies’ revenue from costly, redundant data retrieval services.
Much like DeepSeek shook the AI ecosystem last year, iFrame’s Asperanto and Sefirot-10 models eliminate the need for retrieval pipelines and fine-tuning altogether, fulfilling a recent prediction made by former Google CEO Eric Schmidt that infinite context models are on the horizon, aiming to reshape our understanding of agentic AI applications.
For nearly a decade, the artificial intelligence industry has been trapped inside the transformer’s attention matrix - the engine that powers every major AI from OpenAI, Google, and Anthropic, forcing even the most advanced models into a state of digital amnesia.
After three years of stealth mode, iFrame™ is launching the world’s first Large Attention Model (LAM), an architecture that doesn’t just stretch the context window — it makes the very concept obsolete. By removing the attention matrix entirely, iFrame™ has created a model that can natively reason terabytes of data in a single pass: no RAG, no fine-tuning, no parlor tricks. Instead of training a multibillion-dollar LLM to distill and fine-tune it for usable inference, with iFrame™, you simply upload terabytes of data to an attention block, upgrading AI knowledge in seconds.
“For better or worse, I helped AI to escape the Matrix — literally,” says Vlad Panin, iFrame’s founder and creator of the Monoidal Framework, in the recent interview. His breakthrough didn't come from iterating on existing AI research, but from deep work on the mathematics of universe topology, inspired by the work of the famously reclusive Grigori Perelman, who solved the Poincare Conjecture in 2002.
“Everyone is trying to optimize the matrix from within its accepted narratives,” Panin explains. “I was reckless enough to search for a key to a door whose existence is explicitly ruled out by the doctrine of matrix calculation parallelism.”
This is a fundamental challenge to the entire AI hardware and software ecosystem. GPU powerhouses like AWS, Azure, and Google can potentially quadruple their datacenter utilization capacity overnight. iFrame’s architecture is designed from the ground up to operate on decentralized networks, utilizing every bit of available memory across available hardware. It sidesteps the GPU VRAM bottleneck that has made NVIDIA the king of AI and opens a path to a world where massive AI models run on a global network of distributed devices.
Enabling new kinds of products
While other labs celebrate million-token context windows, iFrame™ has already tested its LAM on inputs exceeding one billion tokens with no loss in accuracy.
Imagine a doctor providing an AI with a century of patients' medical history — every lab result, doctor's note, and genomic sequence from birth — along with the complete medical histories of their relatives. The AI can then reason over this entire data fabric natively, spotting patterns invisible to any system that relies on search or retrieval.

“The AI industry’s reliance on vector databases is an admission of failure to build AGI,” Panin states, pulling no punches. “It’s a clever patch for a model that can’t actually read all the documents as claimed in marketing materials. We let the model read everything, because we can.”
A Token Economy That Respects Your Wallet
This new architecture enables an entirely different economic model. For developers using tools like Cursor, Base44, or building complex agents, the frustration of refeeding a model the same context — and paying for those tokens every single time — is a massive hidden cost.
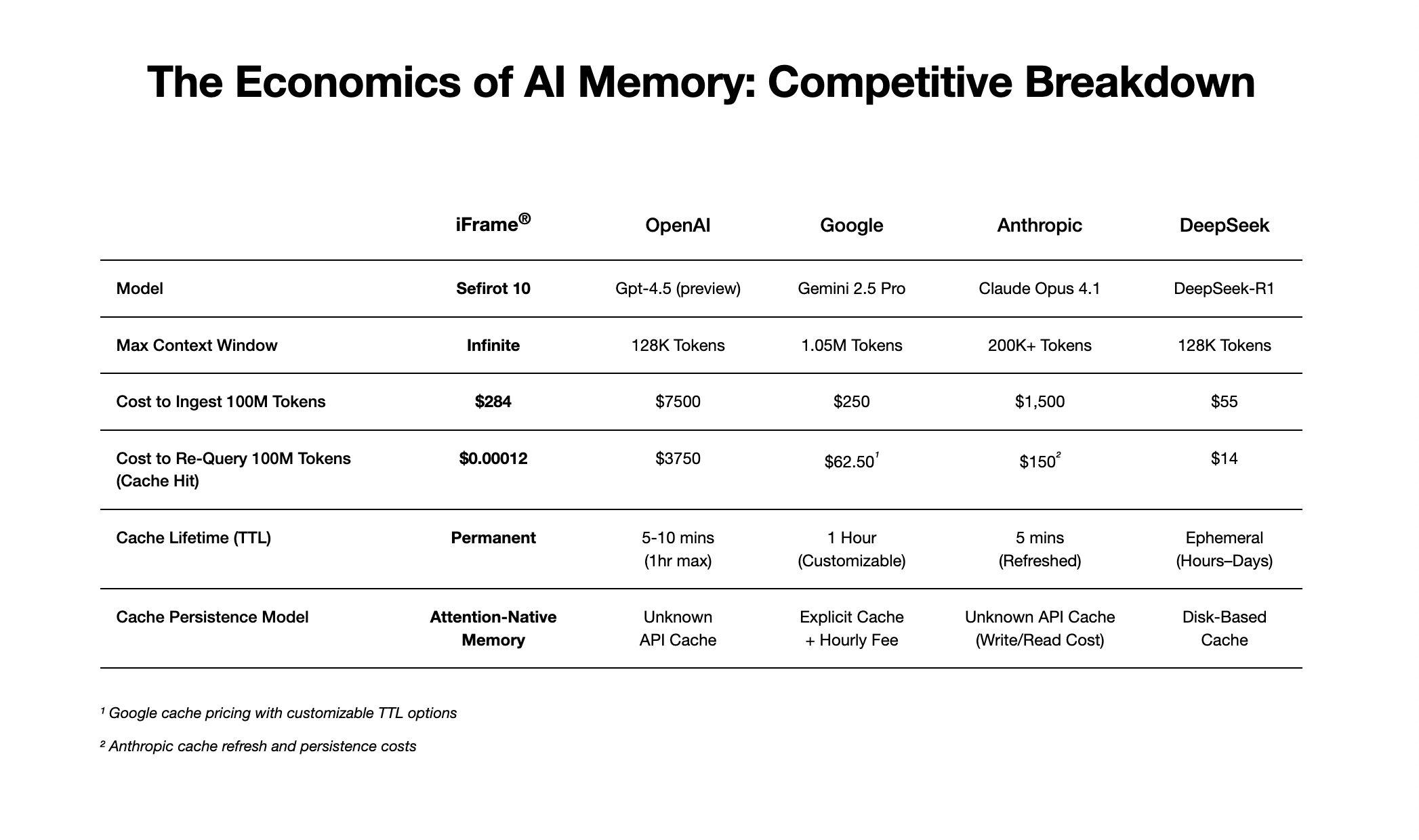
iFrame™ introduces Unlimited Cache and Versioned Context, features that allow any session to be cached indefinitely and reused even with contextual forks.
The pricing structure reflects this new reality:
- Input Tokens: $2.84 per million
- Output Tokens: $17.00 per million
- Cached Input Tokens: $0.0000012 per million
This means re-using a 100 million token codebase for a new query costs a fraction of the initial ingestion price. Users can fork lines of reasoning, allowing teams to run parallel analyses on a shared, persistent context while only paying for the new tokens they generate. The cost is now aligned with generating new insight, rather than repeatedly reminding the AI of what it already knows. iFrame™ doesn't save chat history in a separate database; instead, it focuses on attention-native memory similar to how the human brain converts experience into long-term memory during sleep. This approach eliminates the necessity for extensive and costly model fine-tuning or retrieval-augmented generation (RAG), realigning market expectations regarding the valuation of key beneficiaries exploiting this revenue-generation loophole.
Official Launch, Models, and Availability
The strategic alliance with an undisclosed cloud provider gives iFrame the firepower to train its large attention model, Asperanto, for synthetic data generation, as well as its healthcare-specific reasoning model, Sefirot-10, whose public release is slated for Q4 2025. Meanwhile, starting August 1st, ‘25, enterprise clients can access both iFrame™ models via API. The company also collaborates with EverScale AI to release an SDK that supercharges any of the existing models, such as LLaMA, Kimi, and DeepSeek, with an infinite context window, thereby replacing the need for RAG or finetuning entirely.
The World Economic Forum's "Future of Jobs Report 2025" projects a massive underlying structural shift: an estimated 92 million jobs are expected to be displaced, while 170 million new jobs will be created. With the launch of its unlimited context attention models, iFrame™ joins the short list of companies advancing original AI architecture, amplifying such significant changes in the workforce landscape. Yet, in contrast to the industry’s growing reliance on redundant retrieval and fine-tuning workarounds, iFrame’s approach represents a genuine shift in model design, expanding the boundaries of what’s technically and economically viable in large-scale reasoning for every business and every individual.
Photos accompanying this announcement are available at
https://www.globenewswire.com/NewsRoom/AttachmentNg/69a9e9b8-4dc7-4b7e-9cfc-7c0445e929d8
https://www.globenewswire.com/NewsRoom/AttachmentNg/0ee57d5d-c603-44dc-b3f8-2787ec5eaf96
https://www.globenewswire.com/NewsRoom/AttachmentNg/01bee187-f5ca-4dd7-b492-81bcabeaa850
https://www.globenewswire.com/NewsRoom/AttachmentNg/a77e7c2d-4441-4a42-815f-50543eb5899a
https://www.globenewswire.com/NewsRoom/AttachmentNg/6923bb88-f328-4fa3-a9f3-f8ff83ff0601
https://www.globenewswire.com/NewsRoom/AttachmentNg/b0332aac-cb87-4908-baa1-b7efcce46d23

Contacts: media@iframe.ai

